名前は重いですが、Modelerなら軽くサクっと出来ちゃいます。
・今回作業の概要:
-R言語にも付属している「airquality」データセットで重回帰分析を実施。
最終的なアウトプットはこんな感じ

・データセットについて:
-1973年5月から9月までにおけるニューヨークの毎日の大気品質に関する測定データ。
-153レコード、6フィールド。
-欠損値(NA)含む。
-ダウンロードはこちら。
・実施環境:
-OS:Windows 7
-IBM SPSS Modeler 18 Premium
※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
慣れたら10分で出来ちゃうかも。
1.データセットの読み込み
「入力」パレットにある「EXCEL」ノードから先ほどの「airquality」データセットを読み込ませてください。
自分はxlsx形式で保存しましたが、CSVでも「可変長ファイル」ノードで読み込み可能です。

こちら、「プレビュー」ボタンでデータ内容を確認すると、ユーザー欠損値として「NA」が記載されていることがわかります。

2.「置換」ノードの配置
「フィールド設定」パレットから「置換」ノードを配置してください。
・対象フィールド:全フィールドを入れてください。
・条件:@FIELD == "NA" (「対象フィールドで選択した各フィールドにおいてNAがあった場合」の意味)
・置換後:undef (「SPSS Modelerの欠損値である「$null$」に置き換える」の意味)

3.「フィールド作成」ノードの配置
「Ozone」と「Soloar.R」フィールドが「カテゴリ」になっています。下記のように設定してください。
CLEM式は式ビルダーを使用しても手入力でもOKです。
・フィールドリスト:当該フィールドを選択
・CLEM式:to_real(@FIELD) (「@FIELDで指定したフィールドを実数に変換する」の意味)

4.「フィルター」ノードを配置
前述の「フィールド作成ノード」で変換する前のフィールドは不要なので、「フィルター」列の矢印をクリックして以降のストリームに流れないようにします。

5.「データ型」ノードの配置
「データ型」ノードを開き、「Ozone」と「Soloar.R」 の尺度を「連続型」に変更します。

6.「線型回帰」ノードを配置
ここからが本番です。「モデル作成」パレットから「線型回帰」ノードを配置してください。
今回は「Ozone」の値を予測する重回帰モデルを作ります。
「フィールド」タブでは下記のように設定してください。
・対象:Ozone
・入力:Wind、Temp、Solor.R

「モデル」タブにある「方法」では、「ステップワイズ法」を選択してください。
ざっくり書くと下記の通りですが、ステップワイズ法の方が便利ですね。
・強制投入法:入力欄で指定した説明変数を全て使用する方法
・ステップワイズ法…SPSSが自動的に有意な説明変数を増やす方法
・ステップワイズ法…SPSSが自動的に有意な説明変数を増やす方法

「エキスパート」タブでは、「モード」を「エキスパート」に選択し、下記ダイアログのようにオプションを選択してください。

このあと、「実行」ボタンを押してください。ストリーム上にナゲット(金色の菱形オブジェクト)が配置されます。
7.ナゲットを開く
「モデル」タブを見ると、「予測変数の重要度」グラフが表示されます。あら、Tempが思ったよりも高いですね。

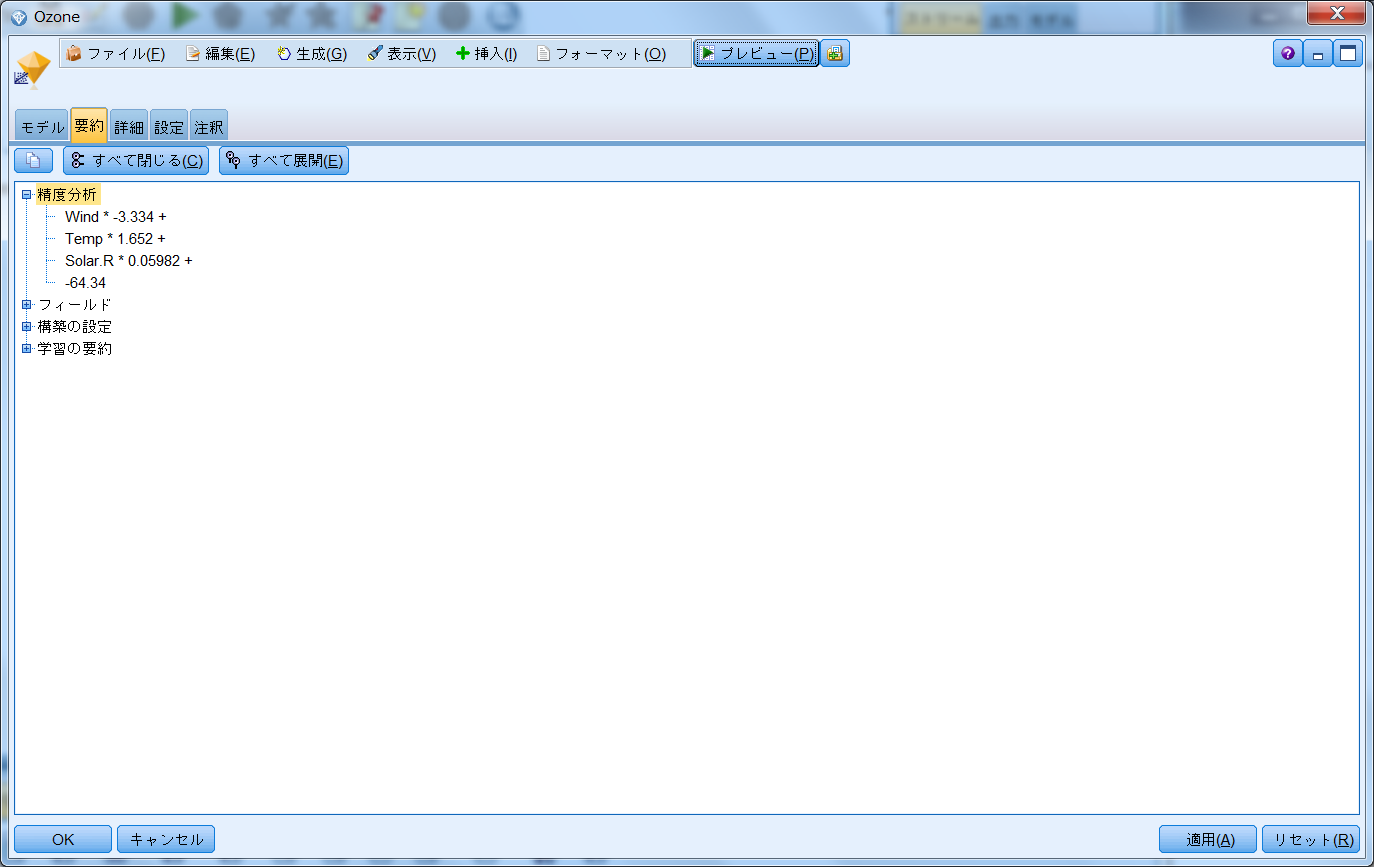
「要約」タブの「精度分析」では、本モデルにおける各変数の影響度を見ることができます。
<モデル式>
$E-Ozone(予測値)=Wind * -3.334 + Temp * 1.652 + Solar.R * 0.05982 - 64.34
$E-Ozone(予測値)=Wind * -3.334 + Temp * 1.652 + Solar.R * 0.05982 - 64.34
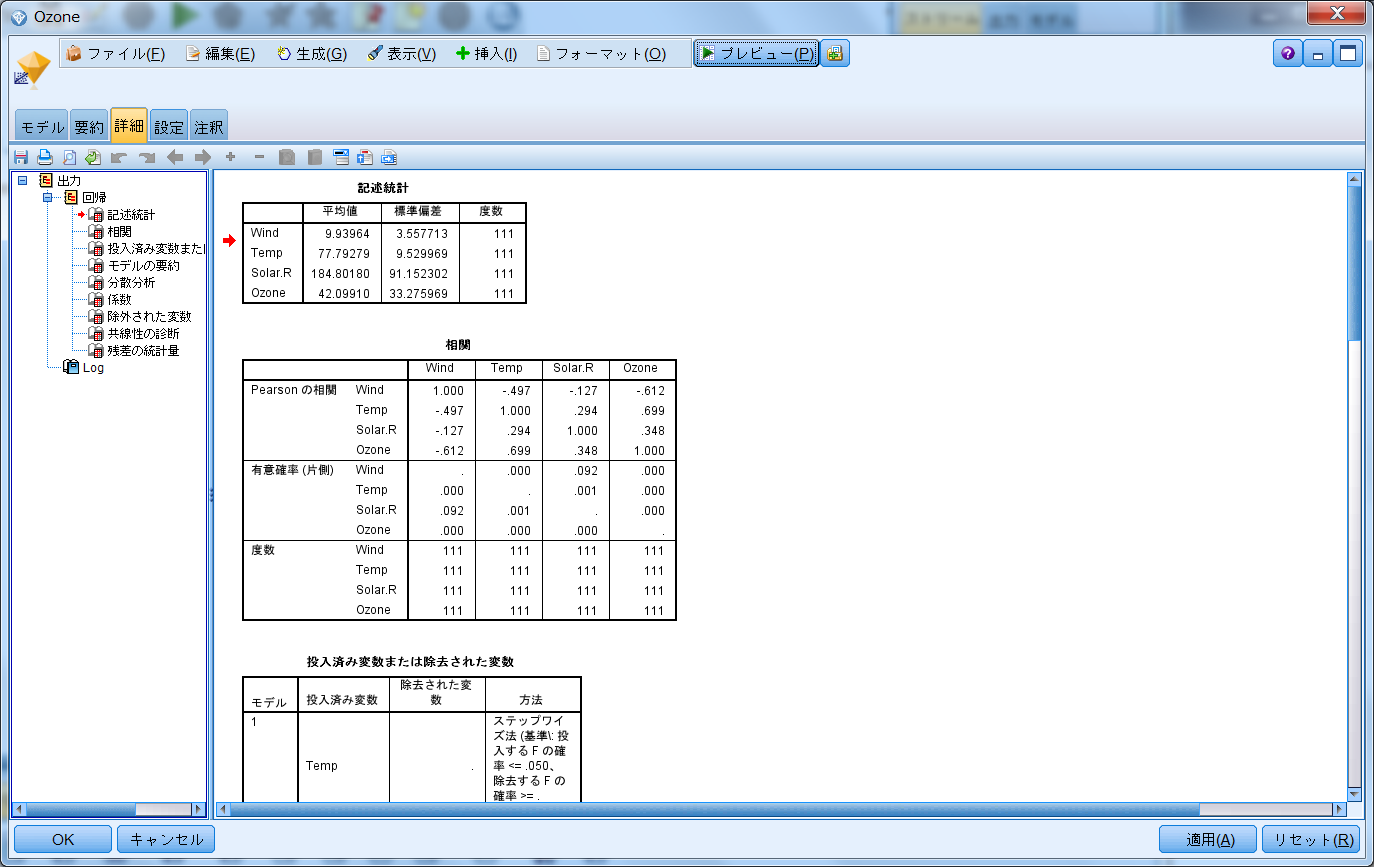
「記述統計」表です。
Pearsonの相関で、「Temp」と「Ozone」の相関係数が「0.699」。
この値が「0.8」を超えると、ワカチコ♪ワカチコ♪
・・・じゃなくって、マルチコ~多重共線性の可能性が高いので、選択する説明変数を再考した方がよいです。
そういえば、「予測変数の重要度」で「Temp」がちょっと高過ぎかなぁと思ったのも納得です。
続いては「モデルの要約」表。
最終モデルの「モデル3」における「調整済みR2乗」が「0.595」なので、とても良いと言うほどでもないですが、そこそこのモデルと言えそうです。
(1.0に近いほど良いモデルと言えます。逆に「赤池情報基準」は低いほど良いです)

「分散分析」表の「モデル3」における「有意確率:0.000」なので有意と言えます(使えるモデルと言うこと)

「係数」表。
「モデル3」における「T値」の絶対値がいずれも2.0以上、有意確率が0.05以下なのでモデル式に入れても大丈夫そうです。
また、多重共線性を見るVIFも10以下なのでこのままで良さそうですね。

最後に「残差の統計量」。
標準偏差と残差の値が極端に離れていないのと、残差の標準偏差が予測値の標準偏差よりも小さい点を確認してください。

以上です。
次回は、この重回帰モデルで作ったSPSS Modelerのストリームファイルを使って、Bluemixの「Predictive Analytics」に投入して遊んでみます。
その他:SPSS Modeler関連エントリー
(無料)Watson StudioでSPSS Modeler flowの決定木を動かす
(Watson)Personality InsightsのJSONをR言語でパースしてみた
Watson Studioの「Data Refinery」機能で「馬の疝痛(せんつう)」データを眺めてみた。
SPSS Modelerでアソシエーション分析がしたいっ! (前処理編〜縦持ちを横持ちへ)
http://sapporomkt.blogspot.jp/2017/06/spss-modeler.html
SPSS Modelerでクラスター分析をやってみた(K-Means)
http://sapporomkt.blogspot.jp/2016/08/spss-modelerk-means.html
SPSS ModelerからStatistics用ファイルを出力する方法
http://sapporomkt.blogspot.jp/2016/08/spss-modelerstatistics.html
(SPSS Modeler)馬の疝痛データを誰でもカンタン決定木♪
http://sapporomkt.blogspot.jp/2016/07/spss-modeler.html
「SPSS Modeler Text Analytics」によるテキストマイニング(データ読み込みからグラフ化)
http://sapporomkt.blogspot.jp/2016/07/spss-modeler-text-analytics.html
「SPSS Modeler」におけるデータ操作及びシーケンスデータの取り扱いまとめ
http://sapporomkt.blogspot.jp/1970/01/spss-modeler_1.html
SPSS Modelerでリーディングサイアーデータ分析:前処理(レコード追加等)
http://sapporomkt.blogspot.jp/2016/05/spss-modeler.html
SPSS Modelerで「サイアー/ブルードメアサイアー」データをレコード結合
http://sapporomkt.blogspot.jp/2016/05/spss-modeler_13.htm